Insights
How companies can leverage ChatGPT and other Large Language Models
Feb 7, 2023

AI Summary
I co-wrote this piece with Notion AI and ChatGPT. I’ll make a note when it’s me (like now) or when it’s the AI (like this ~tldr ChatGPT wrote for me):
ChatGPT is an open-source NLP system based on transformer-based language models that enables developers to build conversational AI applications.
Large language models (LLMs) can be used for NLP tasks, chatbots and virtual assistants, content generation, and question answering.
LLMs have limitations, including computational cost, environmental impact, bias, lack of interpretability, and limited knowledge.
Companies can use LLMs to streamline productivity, improve products and services, and reduce costs.
Responsum is an expert in helping companies think through their challenges and opportunities and then build solutions.
Actually, that last bullet is mine. Let’s jump in.
What is ChatGPT?
Here’s what Notion’s writing assistant wanted you to know:
ChatGPT is an open-source natural language processing (NLP) system that enables developers to build conversational Artificial Intelligence (AI) applications. The system is based on transformer-based language models trained on large datasets of conversational exchanges (aka Large Language Models). ChatGPT aims to enable developers to create more interactive and engaging AI applications that can understand and respond to natural language input. ChatGPT applications are used in various contexts, from customer service to virtual assistants. With ChatGPT, developers can create applications that allow users to ask questions, receive answers, and engage in natural conversations with AI.
What exactly do those terms mean?
I asked Notion AI to define some terms for us.
Natural Language Processing (NLP)
Refers to the use of computer algorithms to interpret and understand human language. It is used to enable machines to understand and interpret human language and to be able to communicate with humans. NLP is used to process large volumes of text, such as in natural language processing tasks like machine translation, text summarization, and sentiment analysis. It is also used in voice recognition systems and automated customer service applications.
Conversational AI
A form of Artificial Intelligence (AI) that enables machines to interact with humans conversationally. It is a form of NLP that uses machine learning algorithms to understand and respond to natural language input. Conversational AI applications are used in everything from virtual assistants and customer service agents to chatbots and language-based games.
Large Language Models (LLMs)
Another type of Artificial Intelligence (AI) that use large datasets of conversational exchanges to enable machines to learn and understand natural language. These models are trained on large amounts of conversational data and allow the machine to make predictions and produce natural language responses. They can be used to power conversational AI applications, such as virtual assistants, customer service agents, chatbots, and language-based games.
How was ChatGPT created and how does it work?
Here’s what Notion’s AI wanted you to know…
ChatGPT was created by the Notion AI team, a group of AI researchers and engineers who have been developing AI applications for over a decade. The team used the latest advancements in natural language processing and machine learning to create ChatGPT. The system is based on transformer-based language models that are trained on large datasets of conversational exchanges, allowing it to understand natural language input and provide natural language responses. The team also incorporated the latest research in AI to ensure that ChatGPT is able to provide accurate, natural language responses.
Unfortunately, that’s not entirely true so let’s ask ChatGPT…
ChatGPT was created by OpenAI, a research organization dedicated to developing and promoting friendly AI. It was trained on a diverse range of internet text, using a transformer neural network architecture and a version of the GPT (Generative Pretrained Transformer) language model. The training process involved fine-tuning the model on a large corpus of text data to enable it to generate human-like text based on the input prompt.
What’s important is what is happening behind the scenes. Let’s ask ChatGPT again…
ChatGPT uses the GPT-3 (Generative Pretrained Transformer 3) language model, which is based on the transformer architecture. GPT-3 is a deep learning model that has been trained on a massive amount of text data to generate human-like text. The transformer architecture allows the model to effectively process long sequences of data and make use of contextual information, which is essential for generating high-quality text.
GPT-3 works by using a transformer neural network architecture to generate text that is similar to human-generated text. It works like this:
Pre-training: GPT-3 is pre-trained on a massive corpus of text data, which allows it to learn patterns and relationships between words, phrases, and sentences.
Input processing: When given an input prompt, GPT-3 processes the input and generates a hidden representation of the input.
Text generation: Using the hidden representation of the input, GPT-3 then generates text by predicting the next word in a sequence, one word at a time. The model uses its pre-trained knowledge to make informed predictions, which are based on the patterns and relationships it learned during pre-training.
Output: The final output is a sequence of words that form a coherent and human-like response to the input prompt.
GPT-3's ability to generate human-like text is based on its pre-training on a massive amount of text data and its use of the transformer architecture, which allows it to effectively process long sequences of data and make use of contextual information.
What’s a generative pre-trained transformer?
For this section, I asked ChatGPT to write for an 8th grader as it’s previous explanations were still a bit too complex. This is what it said:
A generative pretrained transformer (GPT) is like a smart computer program that can write stories, answer questions, and do other tasks that involve writing or talking.
Think of it like a chef who has been cooking for a long time and knows how to make a lot of different dishes. The chef has learned the different ingredients and recipes, and can use that knowledge to cook up new dishes quickly and easily.
The GPT works in a similar way. It has been taught how to write and talk by reading lots of books, articles, and other written material. This is like the chef learning all the different ingredients and recipes.
Now, when the GPT is asked to write or talk about a specific topic, it can use its pre-learned knowledge to come up with new and interesting things to say, just like the chef can use their knowledge to cook up new dishes.
The "generative" part of the name means that the program can generate new things, like writing a story. The "pretrained" part means that it was taught before it started working on its own, so it doesn't have to start from scratch every time it's given a new task.
GPT-3 refers to the third iteration of the model. Each model has been trained on more and more data.
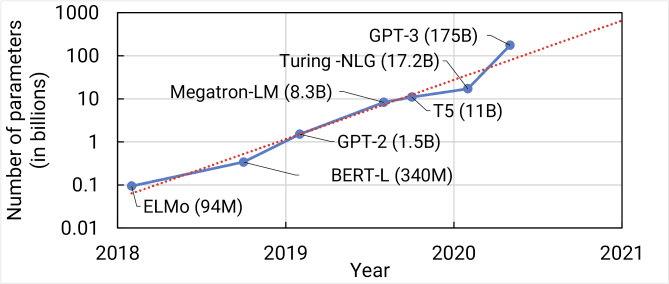
(Adam again)
OpenAI is actively working on GPT-4 and there is plenty of speculation. Will it be trained on more data? Will it have more compute power? It’s likely a combination of both, but more on that in another post.
Why is this exciting?
It’s me again. We’ve gone through several false starts with conversational AI-like technologies. Let’s get some of our collective frustrations out of the way:
Chatbots: No, you did not answer my question…where’s the contact form? The early versions, and most current versions, are based on keyword searches or linear decision trees. Not that helpful.
Voice-Assisted Support Agents: Yes, I want to speak with a human. I love the idea, but they rarely answer the complex questions I have that warrant a phone call.
Voice Assistants: Siri is getting better and I’m starting to like it (we’ll talk about training a little later), but the big problem is still processing the audio to text (getting better) and then understanding what I’m trying to do (more on that later).
The release of ChatGPT will be written about as transformational for two main reasons:
Accessibility: It allows millions of people to interact conversationally with an AI that works (for the most part). It felt like magic and showed us what was beyond the conversational AI dark ages.
Innovation: It brought in developers en masse to start building with the technology.
While OpenAI deserves a ton of credit, they definitely aren’t the only players in this space (Google just launched Bard, Baidu has Ernie, and more on the way). What ChatGPT did for them was give them a huge head start in adoption. In reality, most of you have probably interacted with a tool using OpenAI’s technology or another large language model before. GPT-3 was released in 2020 and there have been other versions before it. Here are a few places you may have interacted with a large language model.
Copywriting tools
A conversational assistant inside a product
Call recording and analysis
Siri, Google Assistant, Alexa
Autocomplete
And the list goes on. What was monumental was how fast it was adopted and how fast people are building with the technology.
What are the limitations?
While there’s a ton to be excited about, there are a ton of limitations that we’ll eventually solve for. Let’s ask ChatGPT what it thinks those limitations are:
Computational cost: Training large language models requires a significant amount of computational resources, including GPUs and large amounts of memory. This can be a barrier to wider adoption of these models, especially for organizations with limited resources. (Adam) For reference, it’s been estimated that the cost to train a model with 500 billion parameters is around $100M.
Environmental impact: The energy consumption required to train these models is significant, leading to concerns about their environmental impact.
Bias and fairness: Large language models are trained on biased data, which can result in biased outputs. This can lead to discrimination and unfair treatment of certain groups, and researchers are working on methods to mitigate these biases.
Lack of interpretability: The internal workings of these models are complex and difficult to interpret, making it challenging to understand why they make the predictions they do. This can limit the trust that users have in the models and make it difficult to diagnose and fix errors.
Limited knowledge: Although large language models have been trained on a massive amount of text data, they still have limitations in their knowledge and understanding of the world. They may generate incorrect or misleading information, and they do not have a true understanding of the concepts they are generating text about.
Adam here again. One important thing it left out about ChatGPT in particular is that its training data is from 2021. It lacks context for current information. We have a lot of work to do, but don’t let that slow you down from bringing this incredibly powerful technology to your team or organization.
How should I be thinking about leveraging conversational AI, GPT, and LLMs?
There are two ways to answer this question: Internal versus External (what you can offer your customers)
Let’s look internal first and start with the obvious. It’s highly likely your team is using ChatGPT or similar tools at work today already.
Copy and email writing
Image and video creation
Brainstorming
Summarization
Some of your team may have already created a side-hustle with it and are thinking about quitting their job. We’re about to experience a massive productivity boom. Our team saw this coming several years ago which is why we’ve been working with LLMs inside of large companies.
My first recommendation is to embrace the experimentation so long as it does not pose a material risk to your company. In other words, encourage your team to try out these tools while being mindful that they’re not sharing sensitive data with any of the tools lacking proper security and privacy protocols. What if you created an internal challenge to streamline productivity using these tools (let’s brainstorm how)?
Next, create a special team internally to identify your current productivity bottlenecks. What’s still manual? What takes a lot of team members to do? What requires precise accuracy? Where are big cost centers or risk?
Then take these observations and figure out how you might apply off-the-shelf tools or build something custom to boost productivity (ask us how we do this).
Your organization likely sits on a ton of proprietary data and knowledge. Maybe it’s in your product, in your wiki or knowledge base, in your customer data and CRM, your analytics, your internal knowledge, etc.
Think about all of the data that is unique to you. Now imagine if you could merge your specific data (your brand voice, your copy style, your decision making frameworks, and so on) with a large language model to create something that is uniquely you.
That’s all internal which usually results in reduced costs, increased efficiency, and accelerated revenue when done properly.
Now what about external?
You can follow a similar process to identify where you might be able to significantly improve your products or services.
How can you make it easier for your customers to interact with your product? We’re working with several organizations to “conversationally enable” their platform. Instead of clicking and searching, what if you could just ask?
How can you proactively surface information to your customers?
How can you analyze customer data and provide value-adds like predictions or assistance on the fly?
How can you make your product easier to use?
How can you make your service easier and more enjoyable to deliver?
It’s all about finding the right question to ask, getting curious, and then experimenting. Possibly the biggest question is: what model should I be using?
Let’s see what ChatGPT thinks…
What are the main use cases for Large Language Models in companies?
Natural language processing (NLP) tasks: LLMs can be used for NLP tasks, such as text classification, sentiment analysis, machine translation, and text summarization. They can process large amounts of text data and generate human-like responses, making them useful for improving customer service, content moderation, and other NLP-related tasks.
Chatbots and virtual assistants: LLMs can be used to build chatbots and virtual assistants that can interact with customers and users in a more natural and human-like way. These models can understand the intent behind a user's request and generate appropriate responses, improving the overall user experience.
Content generation: LLMs can be used to generate a wide range of content, such as articles, product descriptions, and summaries. They can generate high-quality content quickly and at scale, making them useful for improving efficiency and reducing the cost of content creation.
Question answering: LLMs can be used to build question-answering systems that can answer questions in a fast and accurate manner. They can understand the context and intent behind a question and generate a relevant answer, making them useful for improving the user experience and increasing the efficiency of information retrieval.
Personalization: LLMs can be used to personalize user experiences, such as personalized recommendations, personalized advertisements, and personalized search results. They can use user data to generate personalized responses, improving the overall user experience.
Final thoughts
I firmly believe that incredible innovation will be unleashed with the advances we’re about to see with this technology. The race has already begun as other large tech giants release their own conversational AI to challenge OpenAI (The Google v. Microsoft battle continues). The question is how do you harness it for good? In the mean time, I urge you to start thinking about the following…
Where can I apply this technology?
What is the right model for my challenge?
What proprietary data do I have to create a specialized model?
How will I train the model?
I’ll cover these in a future post. For now, it’s time to start innovating and if you feel like you could use a thought partner, please reach out so we can brainstorm.
Have fun and good luck.
- Adam Hofmann

stay in the loop